Storing data in databases, especially for those new to database management systems, might initially seem daunting. However, it’s a process that is much simpler than it appears, offering numerous advantages over traditional file storage methods. This article aims to demystify the use of databases for storing different types of data, with a particular focus on the ease of searching and retrieving specific data sets. In previous parts of this series, we explored the basics of data storage, starting with storing data in plain text files. This method, akin to a basic form of object serialization, is straightforward and easy to implement but has limitations, particularly in terms of scalability and efficiency when dealing with large volumes of data.
We then progressed to discuss the serialization of complex objects using Python’s built-in tools for binary file storage. This approach is more sophisticated than plain text storage, allowing for a more structured and compact representation of complex data objects. However, it still lacks some of the key benefits offered by database storage, particularly in terms of data querying and management.
Now, the focus shifts to SQLite, a lightweight and powerful database module included with Python. SQLite is an excellent choice for both large-scale and small-scale projects due to its simplicity and flexibility. It doesn’t require a separate server, making it easy to set up and use, and it stores all data in a single file, simplifying data portability. SQLite supports various data types and offers powerful querying capabilities, making it ideal for projects that require efficient data retrieval and manipulation. Unlike plain text or binary file storage, SQLite allows for the creation of structured queries to retrieve specific data based on certain criteria. This feature is particularly beneficial for scientific and research projects, where sifting through large datasets to find relevant information is a common task.
The transition to using SQLite in Python is facilitated by Python’s native support for this database. Python’s standard library includes the `sqlite3` module, which provides an interface for interacting with SQLite databases. This integration means that Python developers can leverage their existing knowledge of the language to start using SQLite with minimal additional learning. This article and the series as a whole aim to guide readers through the various methods of data storage, from simple text files to more complex database systems like SQLite. Each method has its place, depending on the specific needs of the project. SQLite, in particular, offers a robust and efficient solution for managing and querying data, making it a valuable tool for a wide range of applications.
Understanding Databases
Databases are commonly associated with website functionality, storing user information like usernames and passwords, and are even used by governments for data storage. But their utility extends to smaller projects like lab device control software or data analysis. Conceptually, databases resemble tables with rows and columns, much like spreadsheets or Pandas Data Frames, demanding systematic information storage.
The Complexity of Database Interaction
Interacting with databases often requires learning a new scripting language, such as SQL, for data storage and retrieval. This tutorial introduces SQL basics, sufficient for many practical applications. While using databases typically involves additional software installation (like MySQL or Postgres), Python’s inclusion of SQLite simplifies this, requiring no extra software for the examples discussed here.
Creating a Database Table with SQLite
Getting started with SQLite is a straightforward process that can be easily integrated into your Python projects. The initial steps involve creating a database file and then proceeding to define the structure of your data by creating tables. Here’s a step-by-step guide to getting started:
Creating a Database File
SQLite databases are file-based, which means that the entire database is stored in a single file on your disk. To create or open a database in SQLite using Python, you use the `sqlite3` module. Here’s a simple example:
```python
import sqlite3
conn = sqlite3.connect('AA_db.sqlite')
conn.close()
```In this code, the `connect` function is used to either open an existing SQLite database file or create a new one if it doesn’t exist. The file in this case is named ‘AA_db.sqlite’. The `.sqlite` extension is a convention that helps identify the file as an SQLite database, although you could also use `.db` or other extensions.
Creating a Table
Once you have a database file, the next step is to create a table to store your data. This is done using SQL commands executed through Python’s interface to SQLite. Consider the following example where we create a table to store experiment descriptions and researcher names:
```python
import sqlite3
conn = sqlite3.connect('AA_db.sqlite')
cur = conn.cursor()
cur.execute('CREATE TABLE experiments (name VARCHAR, description VARCHAR)')
conn.commit()
conn.close()
```In this code snippet, a table named `experiments` is created with two columns: `name` and `description`. Both columns are defined to hold text data (`VARCHAR`). The `conn.cursor()` creates a cursor object which is used to execute SQL commands. `conn.commit()` is used to save the changes made, and `conn.close()` closes the connection to the database.
Visualizing Changes
After establishing the database and creating tables, it’s often useful to visualize the structure and content of your database. Tools like SQLite Browser or the SQLite Manager Firefox Add-On can be extremely helpful. These tools provide a user-friendly interface for viewing and interacting with your SQLite databases.
File Extensions
While the `.sqlite` extension is commonly used and helps in identifying the file type at a glance, using `.db` is also quite popular. The choice of extension does not affect the functionality of the database; it’s more a matter of personal or organizational preference.
Starting with SQLite in Python involves a few basic steps: creating or connecting to a database file, creating tables using SQL commands, and optionally using database management tools to visualize and interact with your database. These initial steps lay the foundation for storing and managing data effectively in your applications. SQLite’s simplicity and integration with Python make it an ideal choice for both beginners and experienced developers working on various types of projects.
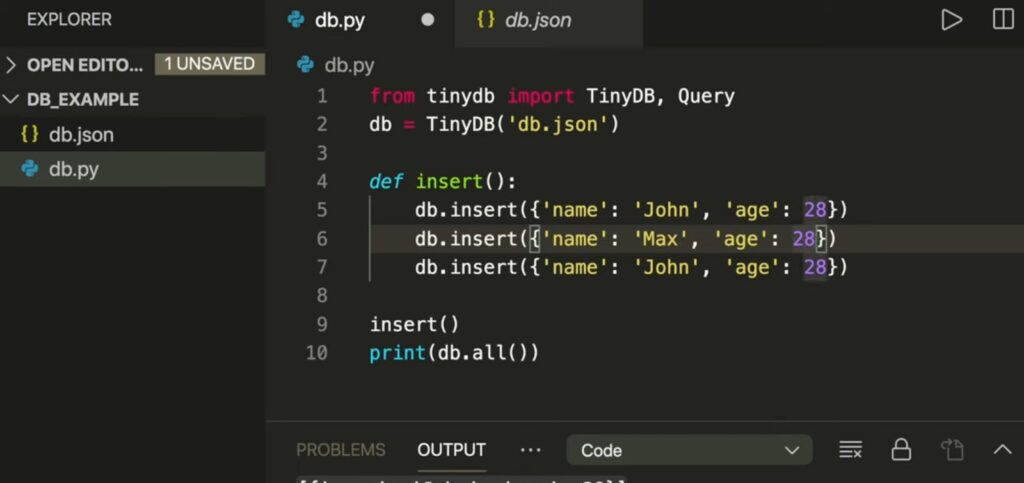
Adding Data to Your Database
Inserting data into a database using SQLite in Python is a straightforward process but requires careful attention to SQL syntax. This is especially true when handling variables in your queries. One of the key practices to ensure safe and secure database interactions is to use parameterized queries. This approach not only simplifies the insertion process but also mitigates the risks associated with SQL injection, a common security vulnerability in database systems.
Using Parameterized Queries
A parameterized query is a way of constructing an SQL statement where placeholders are used for parameters, and the actual parameter values are passed in a separate step. This method helps prevent SQL injection attacks by treating the data and the command separately. Here’s an example of inserting data into the `experiments` table using a parameterized query:
```python
import sqlite3
conn = sqlite3.connect('AA_db.sqlite')
cur = conn.cursor()
cur.execute('INSERT INTO experiments (name, description) VALUES (?, ?)',
('Another User', 'Another Experiment, using "other characters"'))
conn.commit()
conn.close()
```In this example, the `?` placeholders in the `INSERT` statement represent the points where the actual values will be substituted. The values are then passed as a tuple (`(‘Another User’, ‘Another Experiment, using “other characters”‘)`) in the same `execute` call. This separation of data from the command structure is what helps protect against SQL injection.
Security Considerations
While security concerns like SQL injection are more prominent in web applications where user input can be directly used to construct SQL queries, it’s a good practice to be aware of these issues and prevent them proactively. Even in private databases or projects with limited exposure, adopting secure coding practices is essential.
Accessibility and Ease of Use
This guide aims to simplify the process of using databases for those who may be new to SQL and database management. By breaking down the steps — from creating tables to adding data — the guide makes it accessible and manageable, even for beginners. The goal is to demystify the process of database usage and demonstrate how easily SQLite can be integrated into Python projects, offering a robust solution for data storage and management.
In summary, using SQLite in Python for data storage involves a few key practices: understanding basic SQL syntax, using parameterized queries for data insertion, and being aware of security considerations. By following these guidelines, even those new to SQL and databases can effectively utilize SQLite in their projects, benefiting from its simplicity and efficiency.
Data Retrieval Techniques in Databases
After successfully storing data in a database, the next step involves retrieving it. The process can be executed with the following commands:
```python
cur.execute('SELECT FROM experiments')
data = cur.fetchall()
```The first command requests all columns from the ‘experiments’ table, as indicated by the ”. The second command, `fetchall()`, actually retrieves the data. Alternatively, `fetchone()` could be used to retrieve a single record.
Advanced Data Retrieval
For more intricate data retrieval tasks, such as extracting entries associated with a specific user, SQL queries can be fine-tuned to cater to these specific requirements. Using SQLite in Python, these queries can be executed with ease, allowing you to access targeted subsets of data from your database.
Crafting Specific Queries
Consider a scenario where you need to retrieve all entries from the `experiments` table related to a user named “Aquiles”. The SQL command for such a query would look like this:
```python
import sqlite3
conn = sqlite3.connect('AA_db.sqlite')
cur = conn.cursor()
cur.execute('SELECT FROM experiments WHERE name="Aquiles"')
data_3 = cur.fetchall()
conn.close()
```In this example, the `SELECT` statement is used to retrieve all columns (“) from the `experiments` table where the `name` column matches the string “Aquiles”. The `fetchall()` method then collects all the rows that meet this criterion into a list.
Case Sensitivity in SQL
It’s important to note that while SQL commands are not case-sensitive, the data within the database, such as names, often is. This means that searching for ‘Aquiles’ is not the same as searching for ‘aquiles’. The latter would either return a different set of results or none at all if no exact match is found.
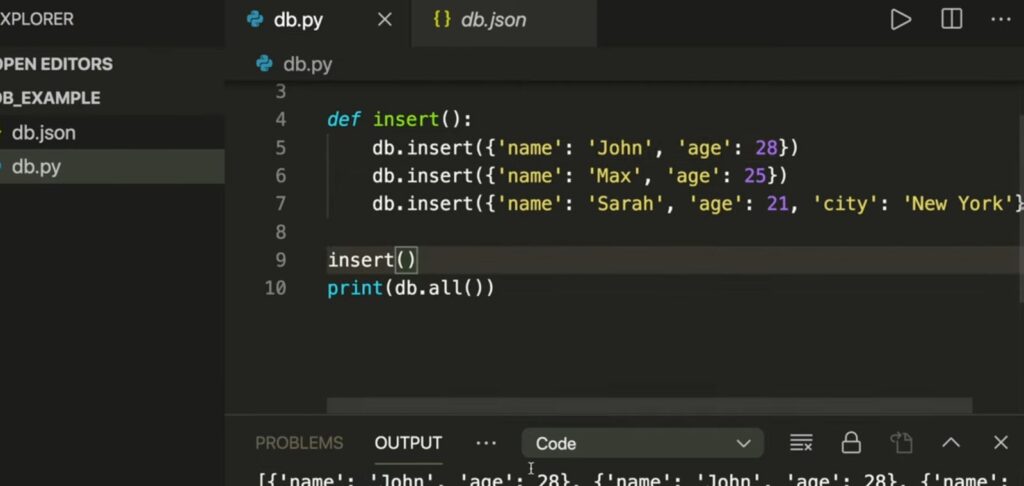
Handling Empty Results and SQL Safety
If the query does not find any matching entries, `fetchall()` will return an empty list. This outcome must be handled appropriately in your code to avoid errors or unintended behaviors.
Moreover, when incorporating variables into SQL queries, it’s crucial to use parameterized queries, as discussed previously. This practice is essential to prevent SQL injection attacks and to ensure the integrity and security of your database. Directly inserting variables into SQL statements without proper sanitization or parameterization can lead to SQL errors and vulnerabilities.
This guide emphasizes the importance of precise SQL query construction for specific data retrieval needs, the sensitivity of SQL to the case of data, and the crucial aspect of maintaining security through the use of parameterized queries. By understanding these concepts, users can efficiently and safely interact with their SQLite databases, harnessing the full potential of this powerful tool for data management in Python projects.
Adding a Primary Key
Identifying specific entries in a database is crucial. Without a primary key, it’s challenging to distinguish between different entries with identical content. The concept is similar to row numbers in a spreadsheet or a Pandas Data Frame, which facilitate data retrieval by line reference.
Creating a primary key in SQLite requires a few steps, including creating a new table and copying existing data. The process involves dropping the existing table and establishing a new one with an ‘id’ column as the primary key:
```python
sql_command = """
DROP TABLE IF EXISTS experiments;
CREATE TABLE experiments (
id INTEGER,
name VARCHAR,
description VARCHAR,
PRIMARY KEY (id));
INSERT INTO experiments (name, description) values ("Aquiles", "My experiment description");
INSERT INTO experiments (name, description) values ("Aquiles 2", "My experiment description 2");
"""
cur.executescript(sql_command)
conn.commit()
```The primary key, ‘id’, uniquely identifies each entry. To retrieve a specific entry, one can use:
```python
cur.execute('SELECT FROM experiments WHERE id=1')
data = cur.fetchone()
```Adding a primary key significantly enhances the efficiency of data retrieval in a database.
Default Values for Fields
Databases are adept at managing a wide variety of data types, providing tools and features that ensure consistency and integrity in data storage. Among these are data types like VARCHAR and INTEGER, which can be tailored to meet specific data requirements, including setting limits on lengths and defining default values. These features play a crucial role in maintaining data consistency, a critical aspect of any robust database system.
Consider the example of a table designed to record scientific experiments:
```sql
CREATE TABLE experiments (
id INTEGER,
name VARCHAR(100),
description VARCHAR(255),
performed_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
PRIMARY KEY (id));
```In this table, each column is defined with a specific data type. The VARCHAR type is used for text fields, with length limits to ensure data uniformity. The INTEGER type is typically used for numerical values, such as an ID. Notably, the `performed_at` column uses a TIMESTAMP data type with a DEFAULT value set to the current timestamp. This default setting ensures that every time a record is added to the table, the date and time of the experiment’s execution are automatically recorded, even if not explicitly provided by the user. Default values can also be applied to other fields, such as the experiment performer’s name. By setting a default value, the database ensures that this information is never missing from a record, maintaining the completeness of the data. This is particularly useful in scenarios where certain data points might be consistently uniform or where omitting them should not prevent record creation.
This guide also delves into advanced data retrieval methods, illustrating how to effectively query and manipulate data within a database. These methods are essential for extracting meaningful insights and performing complex data analysis. Additionally, the importance of primary keys in databases is highlighted. Primary keys ensure the unique identification of each record, eliminating the possibility of duplicate entries and maintaining the integrity of the data. They are a fundamental aspect of database design and crucial for relational databases, where relationships between different tables hinge on these unique identifiers.
Finally, setting default values in databases is discussed. This practice contributes significantly to consistency and completeness in data records. Default values can prevent errors related to missing data and streamline data entry processes, ensuring that the database remains robust, accurate, and reliable. Overall, understanding these aspects of database management — from data types and default values to primary keys and advanced retrieval techniques — is essential for anyone looking to leverage the full potential of database systems in organizing, storing, and analyzing data.
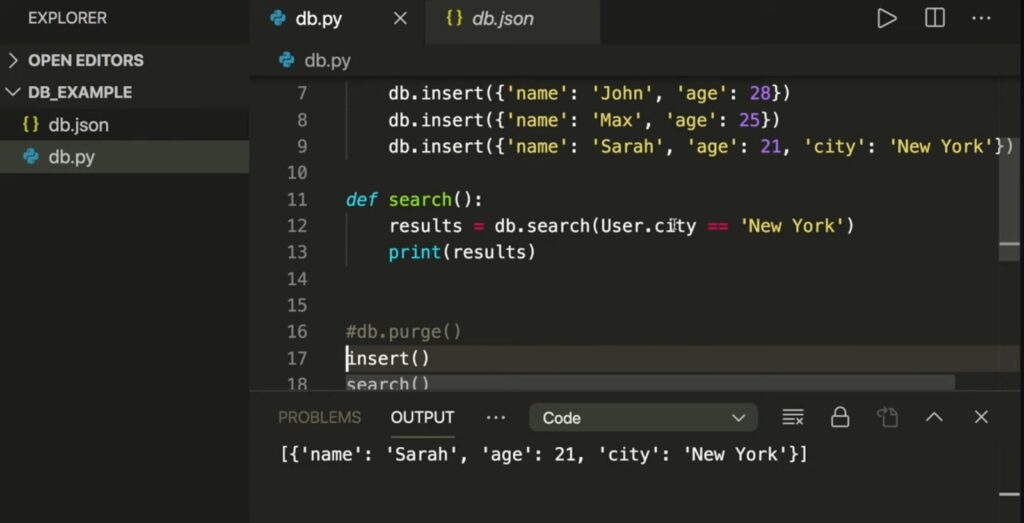
SQLite Data Type Flexibility
SQLite sets itself apart from other database systems like MySQL or Postgres due to its flexible approach to data types and lengths. It primarily defines four field types:
- NULL: Represents a NULL value;
- INTEGER: A signed integer, stored in 1 to 8 bytes based on the value’s magnitude;
- REAL: A floating point value, stored as an 8-byte IEEE floating point number;
- TEXT: A text string, stored in database encoding (UTF-8, UTF-16BE, or UTF-16LE);
- BLOB: A blob of data, stored as input.
Additionally, SQLite introduces ‘affinities’ which indicate the preferred data type for a column. This feature enhances compatibility with other database sources, but can cause confusion when following tutorials designed for different databases. The VARCHAR type used in this series, for example, is not a specific SQLite data type but is supported through affinities and treated as a TEXT field.
Relational Database Advantages
Relational databases become significantly more powerful than simple CSV files or spreadsheets when relationships between data fields are established. In SQLite, this is achieved through the creation of tables and linking them via primary and foreign keys.
For instance, to efficiently store user information related to experiments, one might create a ‘users’ table with each user having a unique primary key. The ‘experiments’ table would then reference these keys:
```python
CREATE TABLE users(
id INTEGER PRIMARY KEY,
name VARCHAR,
email VARCHAR,
phone VARCHAR,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP);
CREATE TABLE experiments (
id INTEGER PRIMARY KEY,
user_id INTEGER REFERENCES users(id),
description VARCHAR,
performed_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP);
```Implementing Foreign Keys in SQLite
Using foreign keys in SQLite is a crucial aspect of database design, particularly for ensuring relational integrity between different tables. In some installations of SQLite, foreign keys are not enabled by default. To activate this feature, a specific command needs to be executed at the beginning of each session. Enabling foreign keys ensures that relationships between tables are strictly enforced, thereby maintaining the integrity of the database.
The command to enable foreign keys in SQLite is as follows:
```python
cur.execute("PRAGMA foreign_keys = ON;")
```This line of code is executed using a cursor object (`cur`) that interacts with the SQLite database. The `PRAGMA foreign_keys = ON;` statement activates the enforcement of foreign key constraints. Once enabled, SQLite will ensure that all foreign key relationships are valid for any insert or update operations. The process of inserting data into tables that utilize foreign keys typically involves a series of steps. For example, in a database with users and their associated experiments, the insertion process would first involve adding a record to the `users` table. Subsequently, when adding records to the `experiments` table, each experiment is linked to a user through a foreign key, typically the user’s ID.
Here’s an essential aspect of using foreign keys: if an attempt is made to insert a record into the `experiments` table with a user_id that does not exist in the `users` table, SQLite will raise an ‘IntegrityError’. This error acts as a safeguard, ensuring that all experiments are associated with an existing user. It’s a key feature that enforces data integrity, preventing orphan records and maintaining coherent relationships within the database. Furthermore, setting fields like `user_id` to `NOT NULL` in the `experiments` table ensures that every experiment entry must be linked to a user. This constraint is another layer of integrity, guaranteeing that no experiment is recorded without an associated user. These practices of using foreign keys and setting appropriate constraints are fundamental in relational database design, ensuring data accuracy and consistency, which are vital for reliable data management and analysis.
Storing Complex Data Types
Storing complex data types, like Numpy arrays, in databases presents challenges due to limited supported data types. However, SQLite allows for the creation of custom data types by registering adapters and converters, enabling the storage and retrieval of arrays as BLOBs.
```python
import sqlite3
import numpy as np
import io
# Adapter and converter for numpy arrays
def adapt_array(arr): ...
def convert_array(text): ...
sqlite3.register_adapter(np.ndarray, adapt_array)
sqlite3.register_converter("array", convert_array)
```Combining Information Across Tables
SQL’s real power and versatility become evident when it’s used to combine data from multiple tables, a common requirement in many real-world applications. This capability is most effectively realized through the use of JOIN statements, which allow for the merging of related data from different tables into a single, coherent dataset. Such operations are fundamental in relational database systems like SQLite, enabling more complex and insightful queries.
Consider a scenario where you have two tables in a database: `users` and `experiments`. The `users` table contains information about users, while the `experiments` table records details of various experiments, each linked to a user. To obtain a comprehensive view that links user information with corresponding experiment descriptions, you would use a JOIN statement. Here’s an example of how this can be achieved:
```sql
SELECT users.id, users.name, experiments.description
FROM experiments
INNER JOIN users ON experiments.user_id = users.id;
```This SQL query demonstrates the power of the INNER JOIN operation. It selects the user ID and name from the `users` table and the experiment description from the `experiments` table. The JOIN is performed on the condition that the `user_id` field in the `experiments` table matches the `id` field in the `users` table. The result is a combined dataset that shows user IDs, their names, and the descriptions of the experiments they are associated with. This example illustrates how SQL efficiently handles and presents relational data. By linking tables through keys and JOIN operations, SQL can extract and combine data in a way that provides more insightful and comprehensive information than would be possible by examining tables in isolation.
SQLite’s flexibility in data types and its prowess as a relational database system make it an excellent tool for managing diverse data management needs. Its ability to store and manipulate complex data types, coupled with the strength of SQL in handling relational data, allows for the creation of powerful and efficient data retrieval and analysis operations. SQLite’s simplicity, combined with its robust features, make it a popular choice for both small-scale applications and complex data management tasks.
Utilizing Databases in Scientific Endeavors
In the realm of scientific projects, particularly for those who are new to development outside web-based environments, the utility and importance of databases might not be immediately apparent. However, databases offer significant advantages that are particularly beneficial in handling large-scale scientific data. One of the primary benefits of using databases in scientific research is their capability to manage and access vast quantities of data without the necessity of loading the entire dataset into memory. This feature is crucial in large-scale scientific projects, which often involve handling massive volumes of data.
Consider, for example, a scientific endeavor that includes millions of measurements resulting from thousands of experiments conducted by numerous users. In such a scenario, it becomes highly impractical and inefficient to attempt to store all this data in memory variables. The sheer volume of data could easily exceed the memory capacity of most systems, leading to performance issues or even system crashes. Databases address this challenge by offering the capability to efficiently query specific subsets of data. Researchers can execute targeted queries to retrieve only the relevant data they need. For instance, they might query measurements made by a particular user within a specific timeframe, or those that match certain experimental conditions. This approach greatly reduces the computational load and memory requirements.
This selective retrieval is particularly advantageous in large-scale scientific projects like astronomical observations, climate modeling, or complex simulations. In such projects, the volume of data can be extraordinarily large, encompassing terabytes or even petabytes of information. Databases enable different research groups or individual scientists to filter and join data efficiently, accessing only the segments that are pertinent to their specific research questions, rather than dealing with the entire dataset. This not only improves efficiency but also enables more effective collaboration among different research teams, each focusing on their specific area of interest while having the ability to access a shared, centralized pool of data.
Databases play a critical role in modern scientific research, particularly in projects characterized by large volumes of data. They provide a scalable, efficient, and practical solution for data management, enabling scientists to focus on analysis and discovery, rather than being bogged down by data handling complexities.
Concluding Thoughts on Database Usage
The primary challenge many scientists face when integrating databases into their projects is learning SQL, the language used for managing and querying databases. Despite this initial learning curve, the benefits of using databases, especially in handling large datasets typical in scientific research, are substantial. This introductory article has aimed to provide foundational concepts in SQL and database management, serving as a stepping stone for further exploration.
For those new to databases, there are numerous resources available, including online tutorials, guides, and courses, many of which are specifically tailored to beginners. These resources often start with basic concepts and gradually progress to more advanced topics, making the learning process manageable and structured.
One aspect that simplifies the transition into using databases for Python developers is the language’s native support for SQLite. SQLite is a file-based database system that requires no separate server or complex configuration, making it an ideal starting point for beginners. Its simplicity, combined with its compatibility with many SQL tutorials found online, provides a gentle introduction to database management. While the use of databases might initially seem excessive for short-term projects, their value becomes increasingly apparent in long-term endeavors. This is particularly true for scientific projects involving software for experimental setups or custom data analysis applications. Databases excel in managing metadata — the data about data, such as experimental parameters, user information, and timestamps.
The combination of databases for efficient metadata management and file systems for storing actual data offers several advantages. Firstly, it provides high portability; sharing data becomes as simple as sharing a database file. Secondly, databases offer an efficient method for searching through and querying extensive metadata collections. This efficiency is particularly important in scientific research, where the ability to quickly and accurately retrieve specific data points or subsets of data can significantly expedite the research process. In summary, adopting databases in scientific projects, despite the initial learning curve associated with SQL, offers significant benefits in the long term. The scalability, efficiency, and structure that databases bring to data management make them an invaluable tool in the arsenal of modern scientific research.